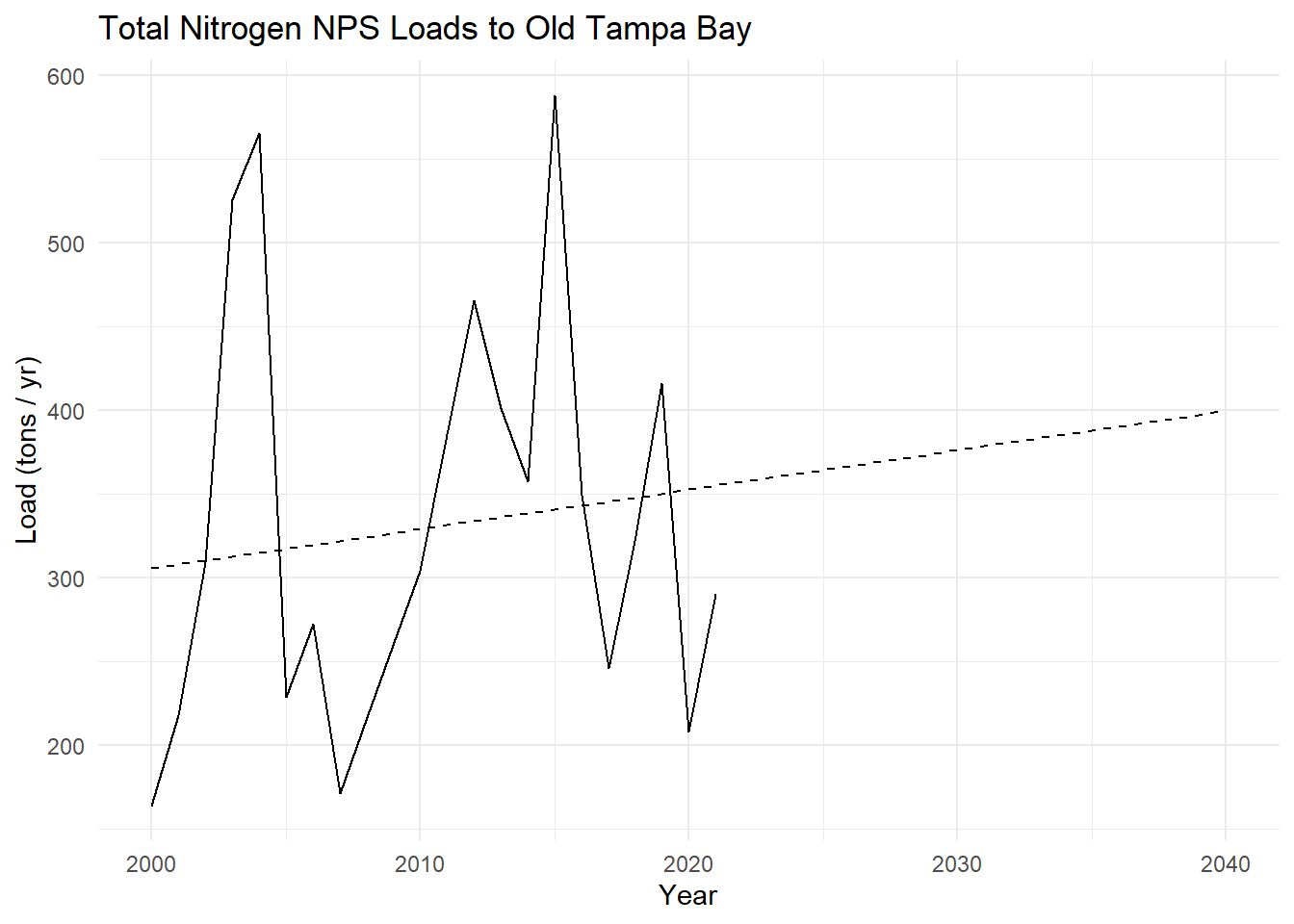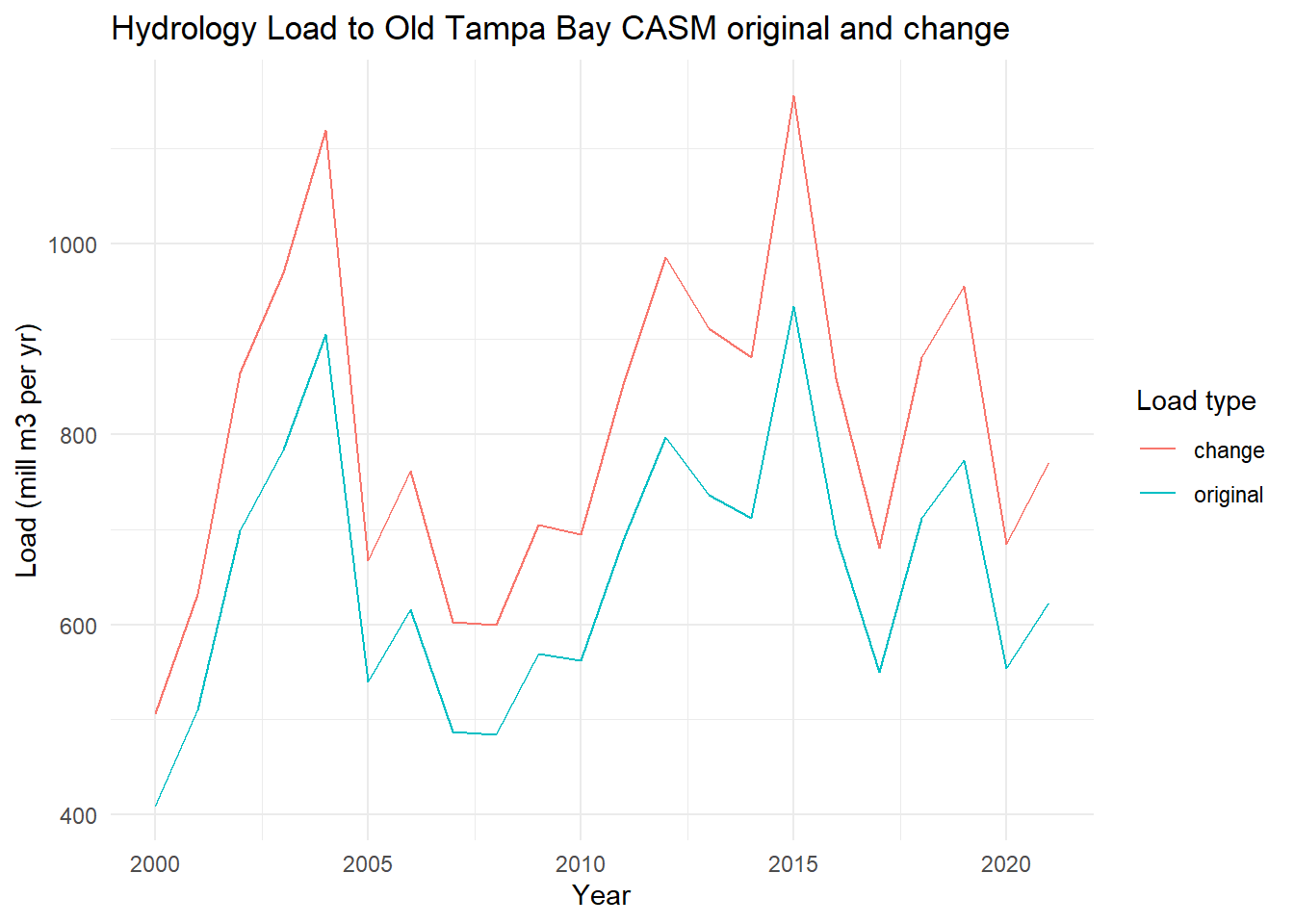This document shows a projection of estimated load change to 2040 based on annual loading estimates from 2000 to 2021.
Total Nitrogen
Code
# regression model of tn_load by yeartnmod <-lm(tn_load ~ year, data = npslddat)# get predictions for years 1985:2040preds <-data.frame(year =2000:2040)preds <- preds |>mutate(tn_load =predict(tnmod, preds) )# plot tn_load as line plot by year# add regression predictionsp <-ggplot(npslddat, aes(x = year, y = tn_load)) +geom_line() +geom_line(data = preds, linetype ='dashed') +labs(title ='Total Nitrogen NPS Loads to Old Tampa Bay',x ='Year',y ='Load (tons / yr)' ) +theme_minimal()p
Code
# estimate means from 2000 to 2021 and 2040means <- preds |>summarise(mean_load_2000_2021 =mean(tn_load[year >=2000& year <=2021]),mean_load_2040 =mean(tn_load[year ==2040]) )# take percent change from 2000 to 2021 to 2040means <- means |>mutate(percent_change = (mean_load_2040 - mean_load_2000_2021) / mean_load_2000_2021 *100 )means
The NPS percent each year is joined to the CASM file and the proportion of the TN load that is NPS is extracted and changed by the estimated percent change from above.
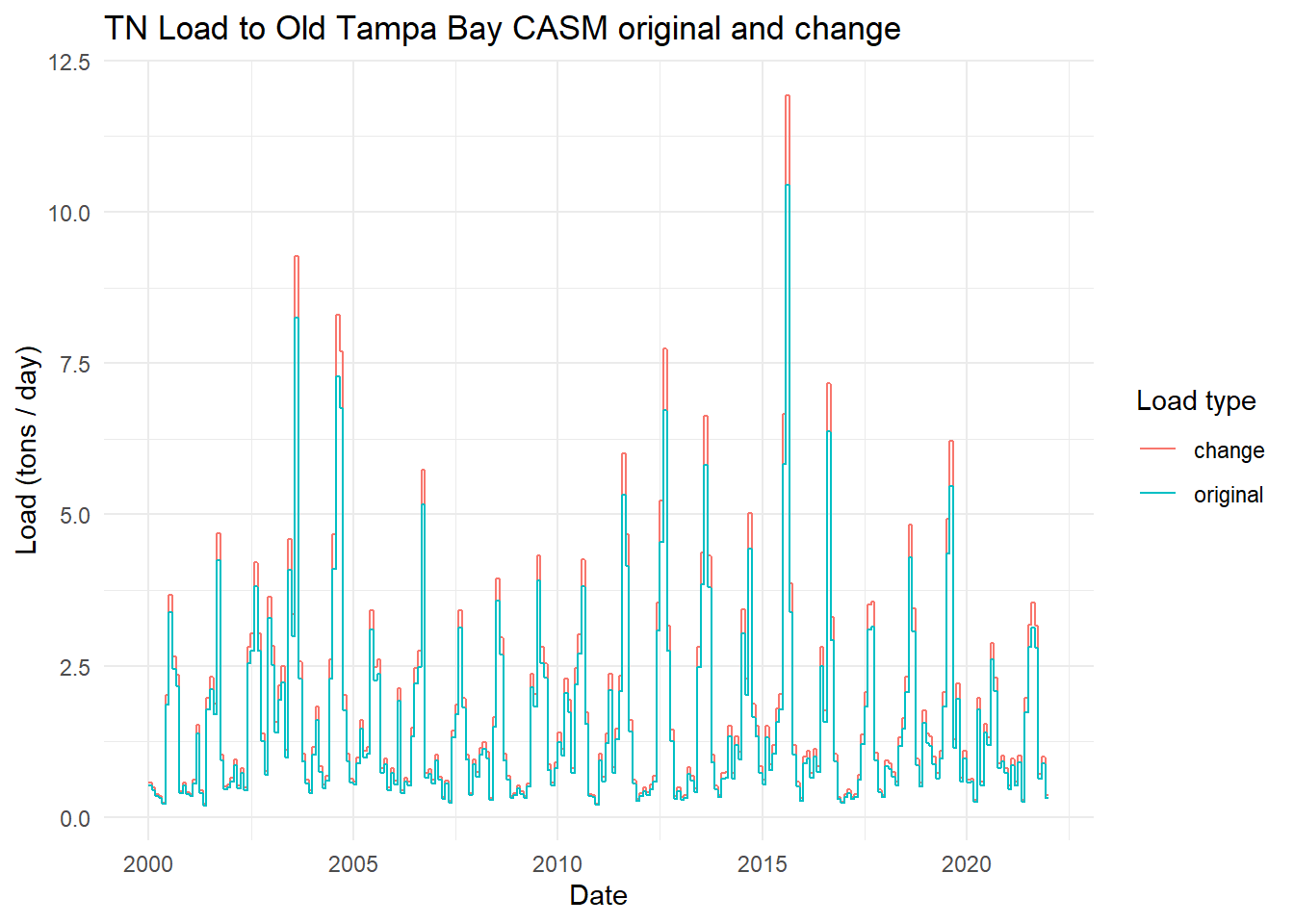
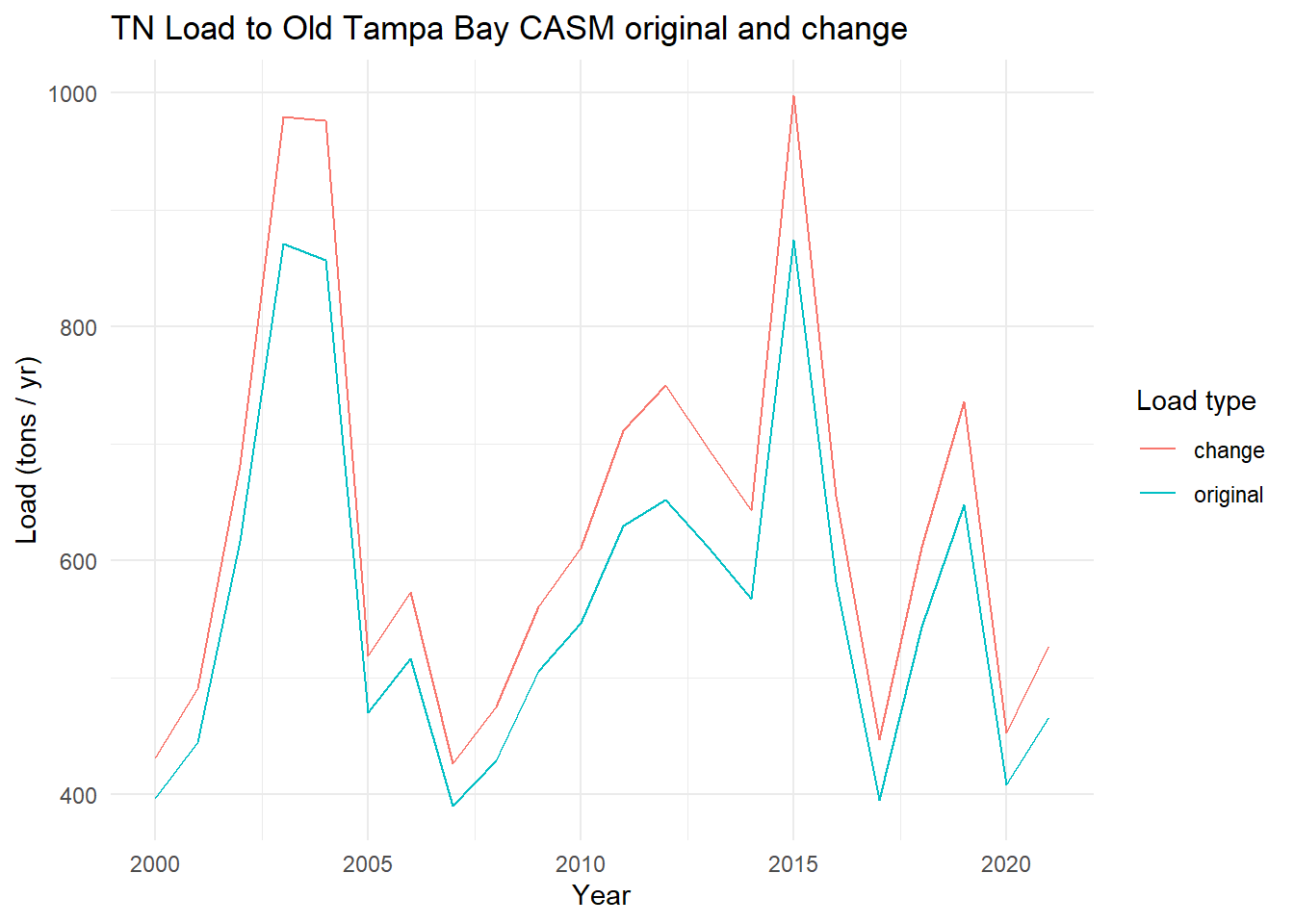
View the total annual TN from before and with the change.
Code
toplo <- casmdat |>summarise(original =sum(TN.tons.d),change =sum(TN.tons.d.chg), .by = Year ) |>pivot_longer(cols =c(original, change), names_to ='var', values_to ='load')p <-ggplot(toplo, aes(x = Year, y = load, color = var)) +geom_line() +theme_minimal() +labs(title ='TN Load to Old Tampa Bay CASM original and change',x ='Year',y ='Load (tons / yr)',color ='Load type')p
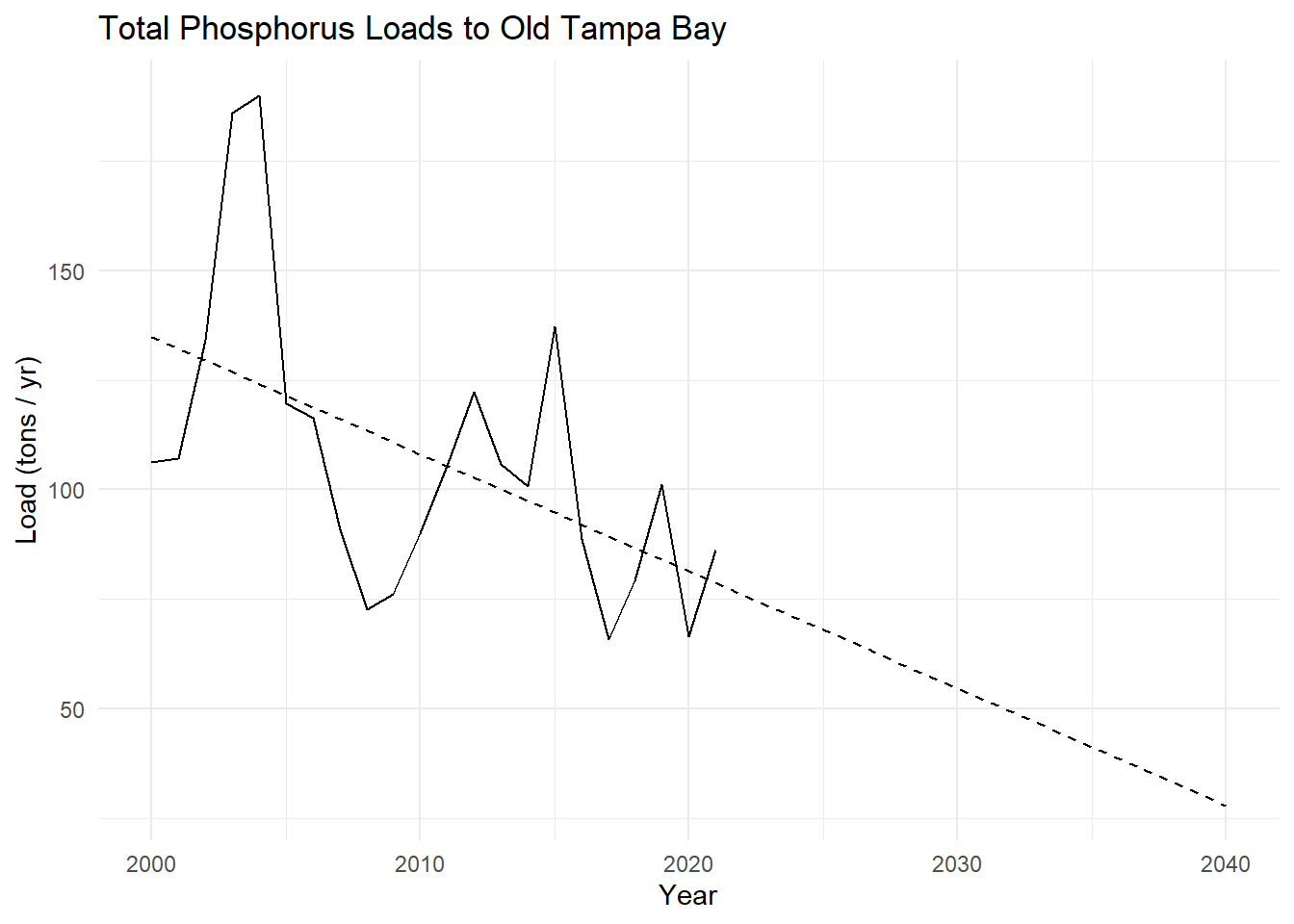
Total Phosphorus
Do the same for total phosphorus.
Code
# regression model of tn_load by yeartpmod <-lm(tp_load ~ year, data = lddat)# get predictions for years 1985:2040preds <-data.frame(year =2000:2040)preds <- preds |>mutate(tp_load =predict(tpmod, preds) )# plot tn_load as line plot by year# add regression predictionsp <-ggplot(lddat, aes(x = year, y = tp_load)) +geom_line() +geom_line(data = preds, linetype ='dashed') +labs(title ='Total Phosphorus Loads to Old Tampa Bay',x ='Year',y ='Load (tons / yr)',color ='Load type') +theme_minimal()p
Code
# estimate means from 2000 to 2021 and 2040means <- preds |>summarise(mean_load_2000_2021 =mean(tp_load[year >=2000& year <=2021]),mean_load_2040 =mean(tp_load[year ==2040]) )# take percent change from 2000 to 2021 to 2040means <- means |>mutate(percent_change = (mean_load_2040 - mean_load_2000_2021) / mean_load_2000_2021 *100 )means
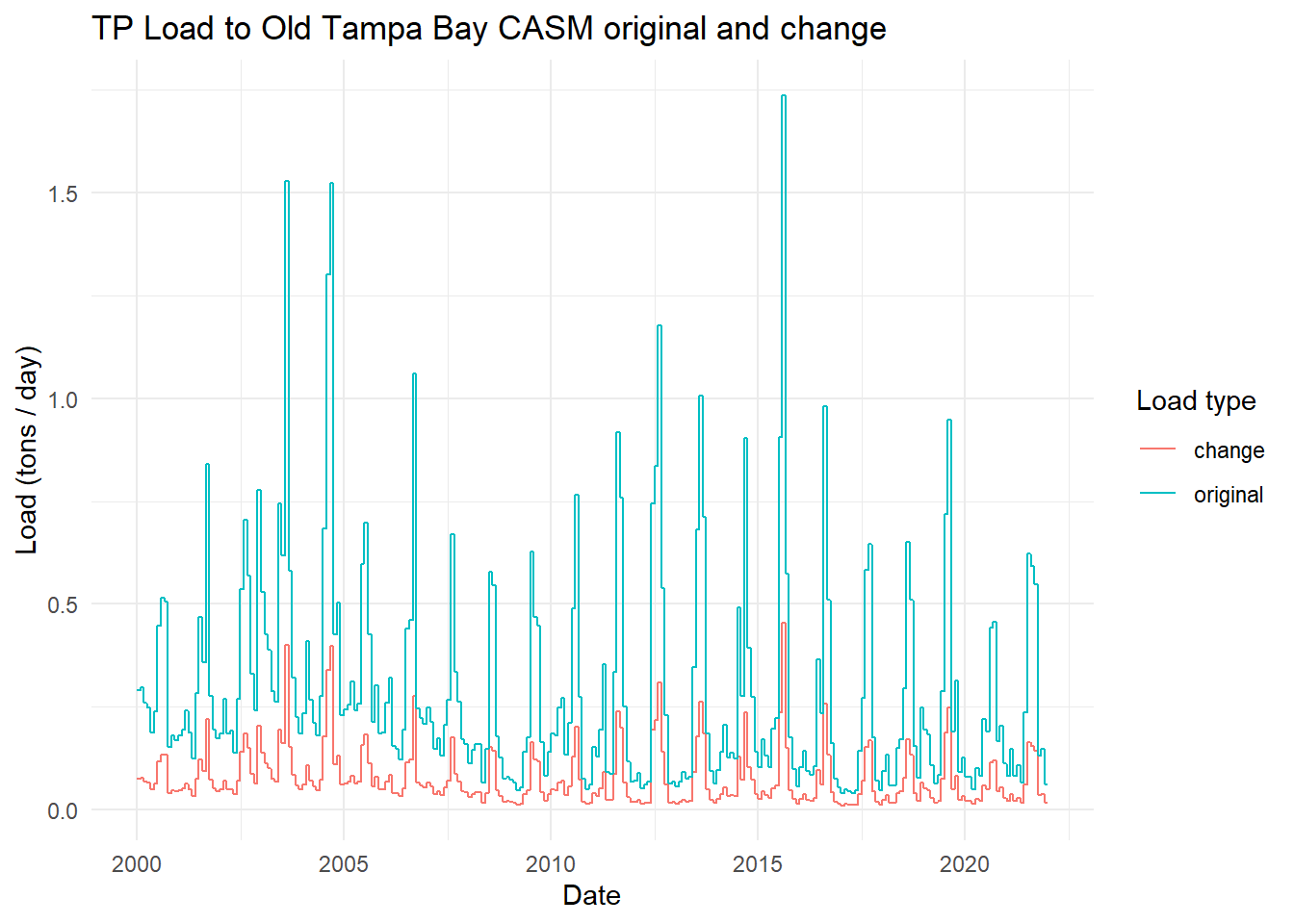
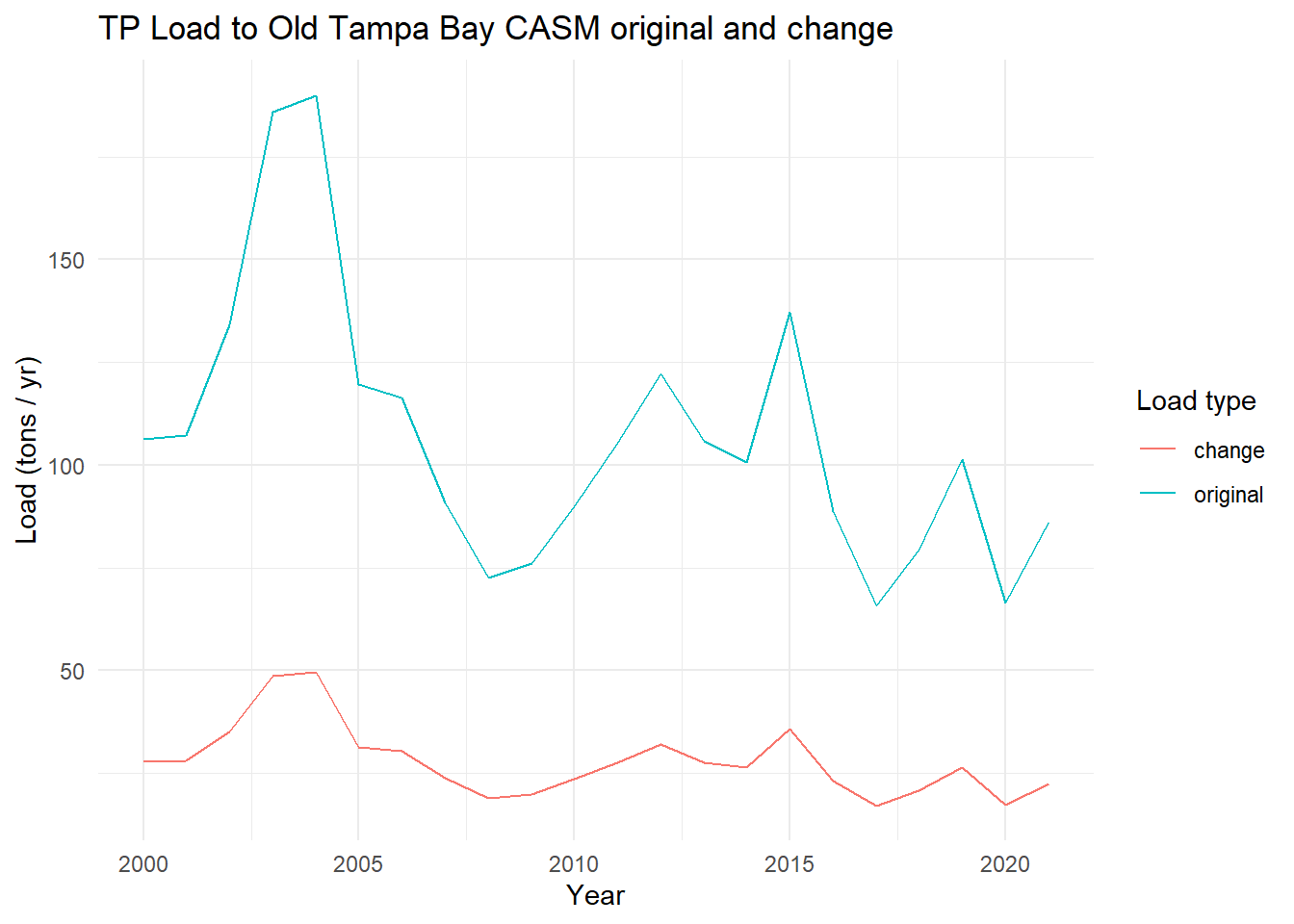
View the total annual TP from before and with the change.
Code
toplo <- casmdat |>summarise(original =sum(TP.tons.d),change =sum(TP.tons.d.chg), .by = Year ) |>pivot_longer(cols =c(original, change), names_to ='var', values_to ='load')p <-ggplot(toplo, aes(x = Year, y = load, color = var)) +geom_line() +theme_minimal() +labs(title ='TP Load to Old Tampa Bay CASM original and change',x ='Year',y ='Load (tons / yr)',color ='Load type')p
Total Suspended Solids
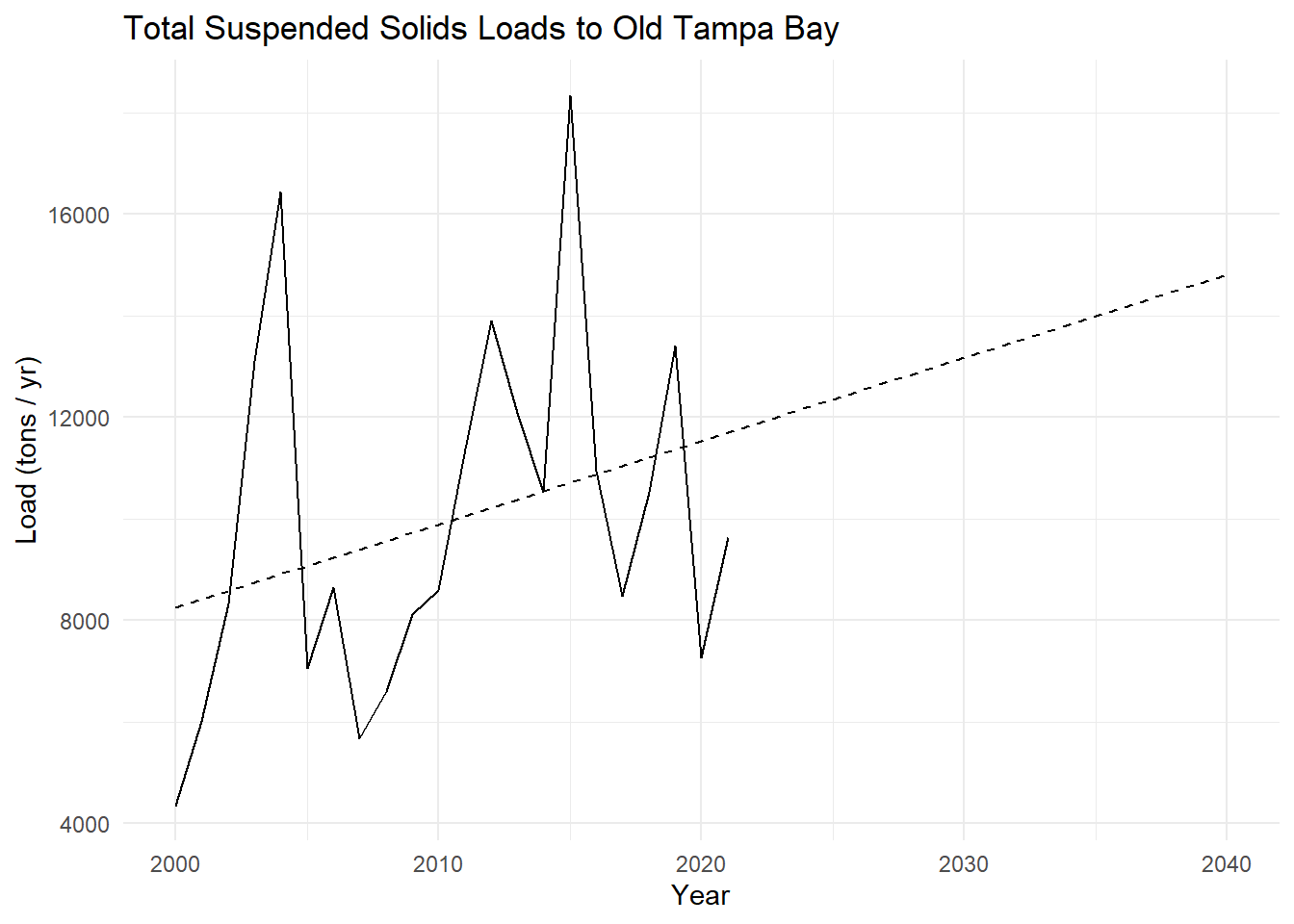
Do the same for total suspended solids.
Code
# regression model of tn_load by yeartssmod <-lm(tss_load ~ year, data = lddat)# get predictions for years 1985:2040preds <-data.frame(year =2000:2040)preds <- preds |>mutate(tss_load =predict(tssmod, preds) )# plot tn_load as line plot by year# add regression predictionsp <-ggplot(lddat, aes(x = year, y = tss_load)) +geom_line() +geom_line(data = preds, linetype ='dashed') +labs(title ='Total Suspended Solids Loads to Old Tampa Bay',x ='Year',y ='Load (tons / yr)',color ='Load type') +theme_minimal()p
Code
# estimate means from 2000 to 2021 and 2040means <- preds |>summarise(mean_load_2000_2021 =mean(tss_load[year >=2000& year <=2021]),mean_load_2040 =mean(tss_load[year ==2040]) )# take percent change from 2000 to 2021 to 2040means <- means |>mutate(percent_change = (mean_load_2040 - mean_load_2000_2021) / mean_load_2000_2021 *100 )means
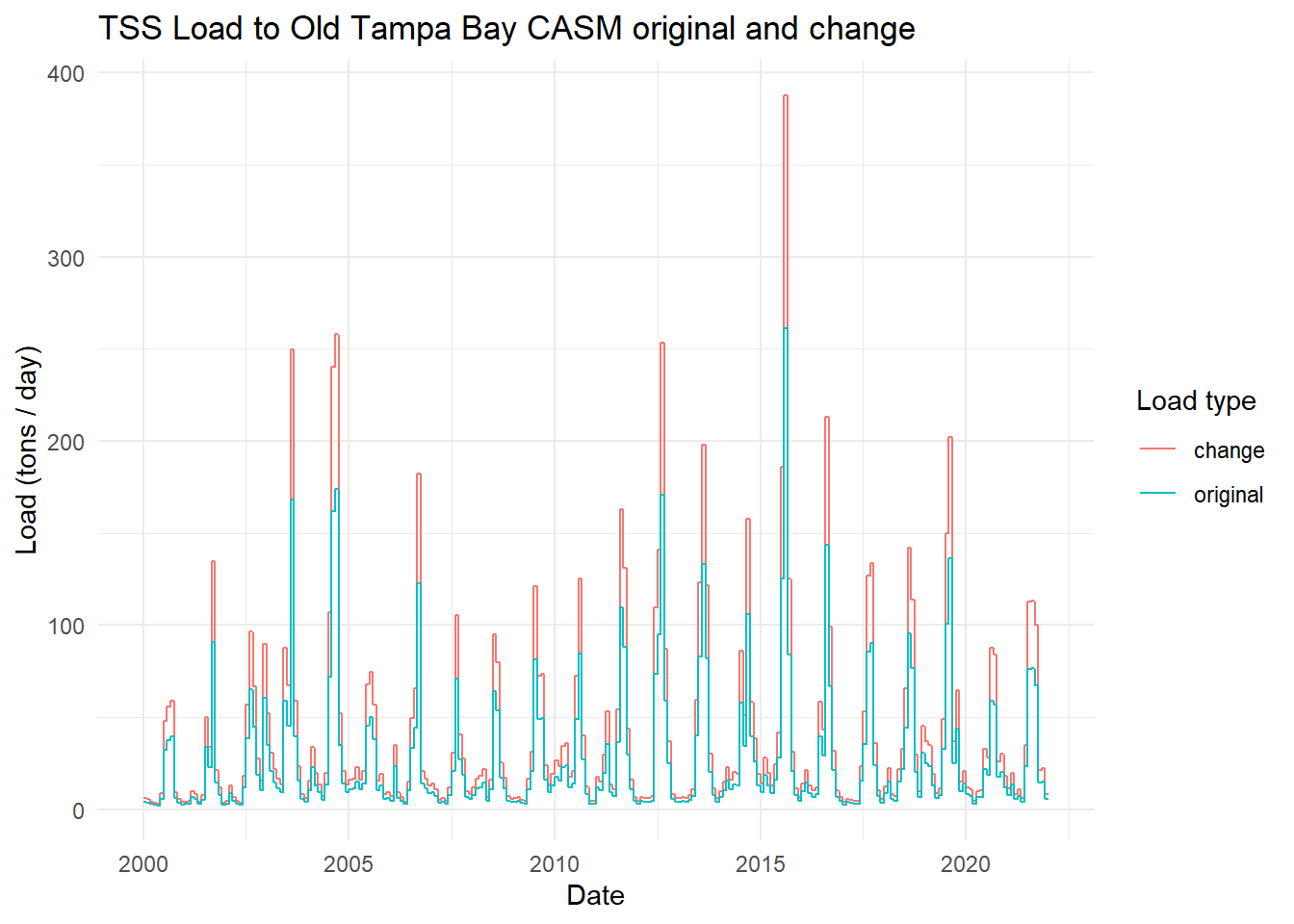
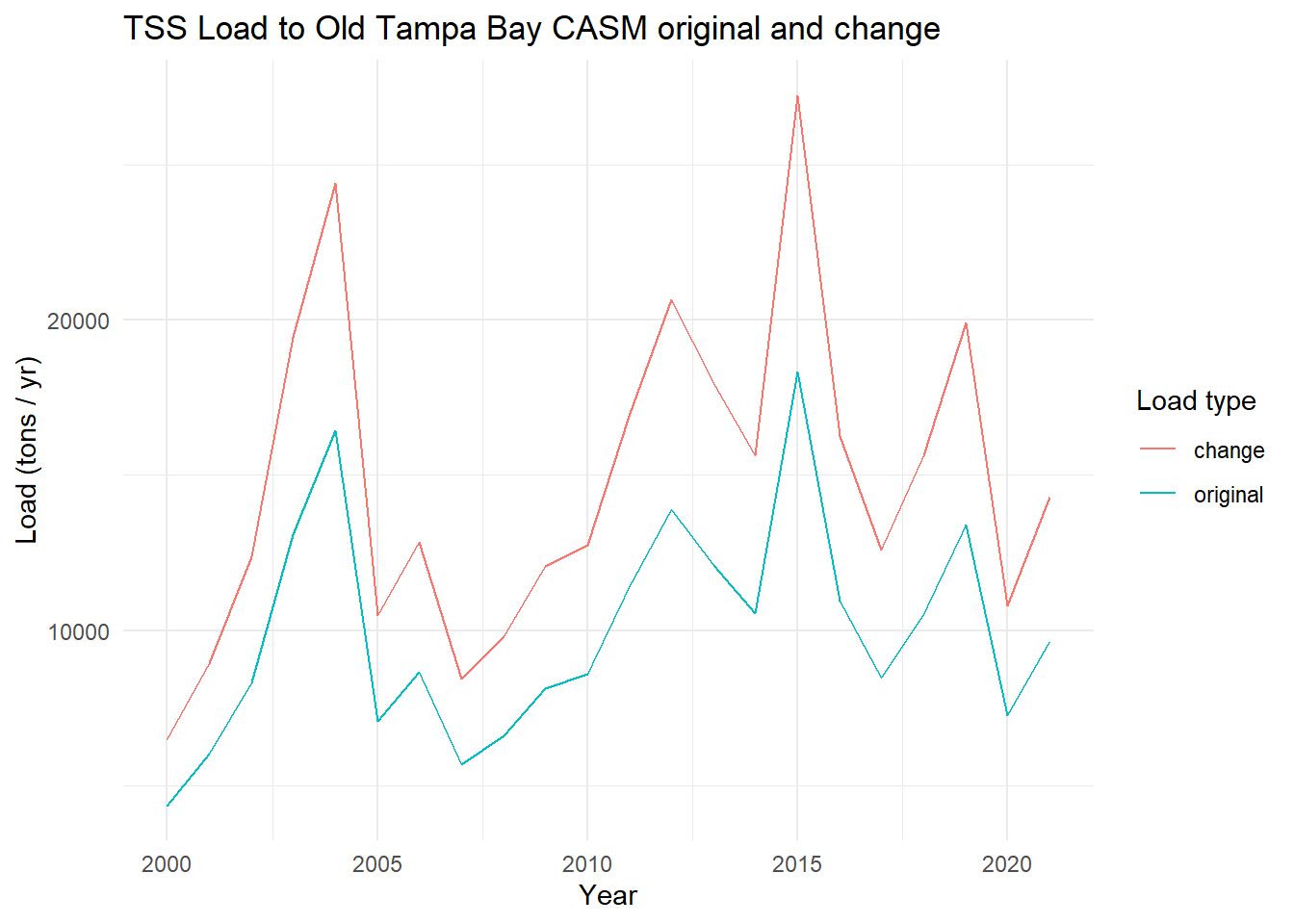
View the total annual TSS from before and with the change.
Code
toplo <- casmdat |>summarise(original =sum(TSS.tons.d),change =sum(TSS.tons.d.chg), .by = Year ) |>pivot_longer(cols =c(original, change), names_to ='var', values_to ='load')p <-ggplot(toplo, aes(x = Year, y = load, color = var)) +geom_line() +theme_minimal() +labs(title ='TSS Load to Old Tampa Bay CASM original and change',x ='Year',y ='Load (tons / yr)',color ='Load type')p
Save CASM file
Write the updated CASM file to disk using the same column widths as the input file.
Code
write_fixed_width <-function(df, file) {# Open file connection con <-file(file, "w")# Write header with exact spacingwriteLines("Year Yr Mo Day DOY TN tons/d TP tons/d TSS tons/d", con)# Write data rowsfor(i in1:nrow(df)) {# Format each column with precise spacing and scientific notation line <-sprintf("%5d %3d %3d %4d %4d %10.4E %10.4E %10.4E", df$Year[i], df$Yr[i], df$Mo[i], df$Day[i], df$DOY[i], df$`TN tons/d`[i], df$`TP tons/d`[i], df$`TSS tons/d`[i])writeLines(line, con) }# Close file connectionclose(con)}casmdat <- casmdat |>select(Year, Yr, Mo, Day, DOY, `TN tons/d`= TN.tons.d.chg, `TP tons/d`= TP.tons.d.chg, `TSS tons/d`= TSS.tons.d.chg)write_fixed_width(casmdat, here::here('data-raw/OTB-DailyLoads2000-2021-chg.dat'))
Hydrology
Code
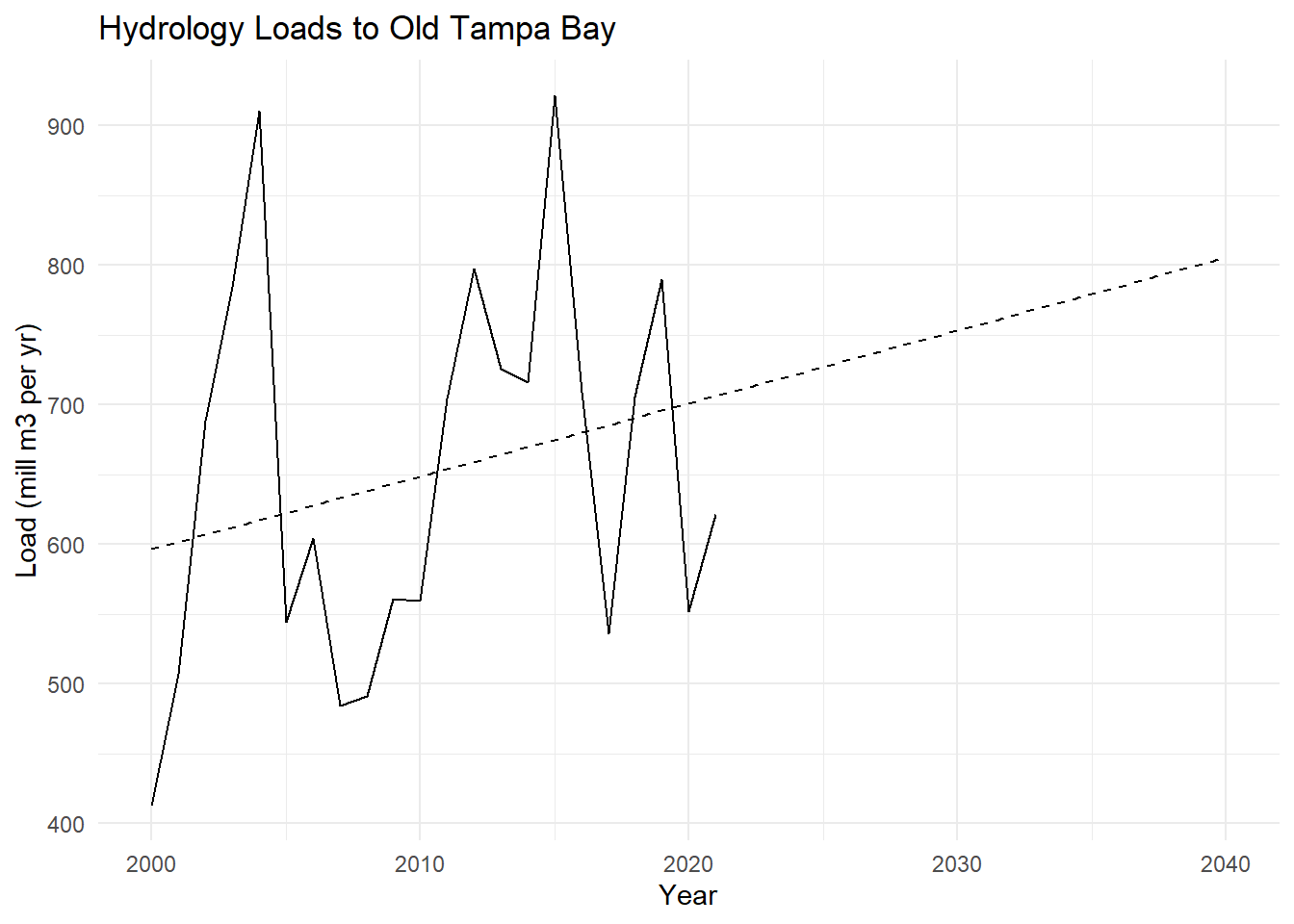
# regression model of hy_load by yearhymod <-lm(hy_load ~ year, data = hydat)# get predictions for years 1985:2040preds <-data.frame(year =2000:2040)preds <- preds |>mutate(hy_load =predict(hymod, preds) )# plot hy_load as line plot by year# add regression predictionsp <-ggplot(hydat, aes(x = year, y = hy_load)) +geom_line() +geom_line(data = preds, linetype ='dashed') +labs(title ='Hydrology Loads to Old Tampa Bay',x ='Year',y ='Load (mill m3 per yr)') +theme_minimal()p
Code
# estimate means from 2000 to 2021 and 2040means <- preds |>summarise(mean_load_2000_2021 =mean(hy_load[year >=2000& year <=2021]),mean_load_2040 =mean(hy_load[year ==2040]) )# take percent change from 2000 to 2021 to 2040means <- means |>mutate(percent_change = (mean_load_2040 - mean_load_2000_2021) / mean_load_2000_2021 *100 )means
Because hydrology is not in the CASM file, we create a daily time series using linear interpolation of the monthly data. This is done to apply the estimated percent change from above.
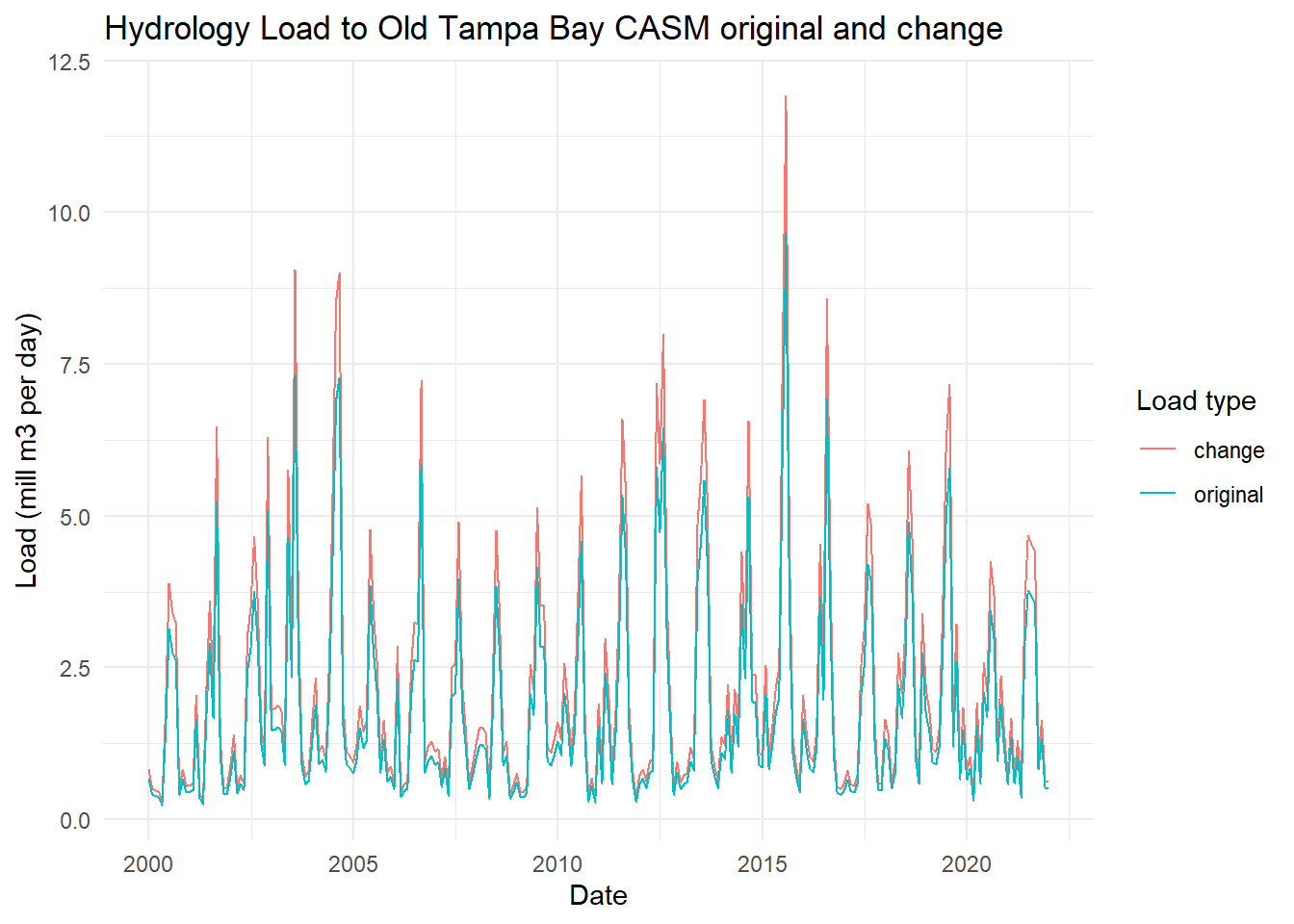
For comparison, the original linearly interpolated hydrology load can be plotted relative to the change.
Code
toplo <- hydlydat |>select(date, original = hy_load, change = hy_load_chg) |>pivot_longer(cols =c(original, change), names_to ='var', values_to ='load')p <-ggplot(toplo, aes(x = date, y = load, color = var)) +geom_line() +theme_minimal() +labs(title ='Hydrology Load to Old Tampa Bay CASM original and change',x ='Date',y ='Load (mill m3 per day)',color ='Load type')p
View the total annual hydrology load from before and with the change.
Code
toplo <- hydlydat |>mutate(Year =year(date)) |>summarise(original =sum(hy_load),change =sum(hy_load_chg), .by = Year ) |>pivot_longer(cols =c(original, change), names_to ='var', values_to ='load')p <-ggplot(toplo, aes(x = Year, y = load, color = var)) +geom_line() +theme_minimal() +labs(title ='Hydrology Load to Old Tampa Bay CASM original and change',x ='Year',y ='Load (mill m3 per yr)',color ='Load type')p
Save Hydrology file
Save the hydrology data in the format received from SB.