R Basics
Get the lesson R script: R_Basics.R
Get the lesson data: download zip
Lesson Outline
Lesson Exercises
Goals and Motivation
R is a language for statistical computing as well as a general purpose programming language. Increasingly, it has become one of the primary languages used in data science and for data analysis across many of the natural sciences.
The goals of this training are to expose you to fundamentals and to develop an appreciation of what’s possible with this software. We also provide resources that you can use for follow-up learning on your own. You should be able to answer these questions at the end of this session:
- What is R and why should I use it?
- Why would I use RStudio and RStudio projects?
- How can I write, save, and run scripts in RStudio?
- Where can I go for help?
- What are the basic data structures in R?
- How do I import data?
Why should I invest time in R?
There are many programming languages available and each has it’s specific benefits. R was originally created as a statistical programming language but now it is largely viewed as a ‘data science’ language. Why would you invest time in learning R compared to other languages?
- The growth of R as explained in the Stack Overflow blog, IEEE rating
R is also an open-source programming language - not only is it free, but this means anybody can contribute to it’s development. As of 2021-04-02, there are 17352 supplemental packages for R on CRAN!
RStudio
In the old days, the only way to use R was directly from the Console - this is a bare bones way of running R only with direct input of commands. Now, RStudio is the go-to Interactive Development Environment (IDE) for R. Think of it like a car that is built around an engine. It is integrated with the console (engine) and includes many other features to improve the user’s experience, such as version control, debugging, dynamic documents, package manager and creation, and code highlighting and completion.
Let’s get familiar with RStudio before we go on.
Open R and RStudio
If you haven’t done so, download and install RStudio from the link above. After it’s installed, find the RStudio shortcut and fire it up (just watch for now). You should see something like this:
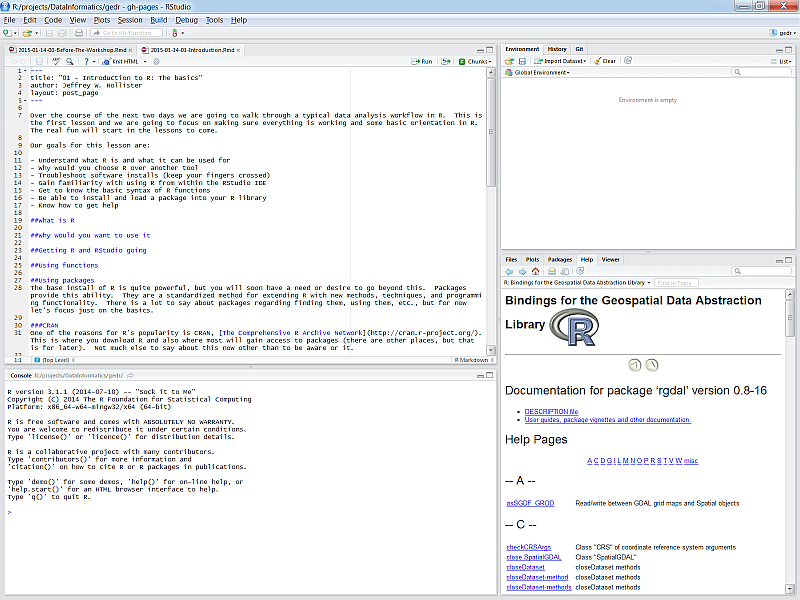
There are four panes in RStudio:
- Source: Your primary window for writing code to send to the console, this is where you write and save R “scripts”
- Console: This is where code is executed in R - you should almost never write code here.
- Environment, History, etc.: A tabbed window showing your working environment, code execution history, and other useful things
- Files, plots, etc.: A tabbed window showing a file explorer, a plot window, list of installed packages, help files, and viewer
RStudio projects
I strongly encourage you to use RStudio projects when you are working with R. The RStudio project provides a central location for working on a particular task. It helps with file management and is portable because all the files live in the same project. RStudio projects also remember history - what commands you used and what data objects are in your environment.
To create a new project, click on the File menu at the top and select ‘New project…’
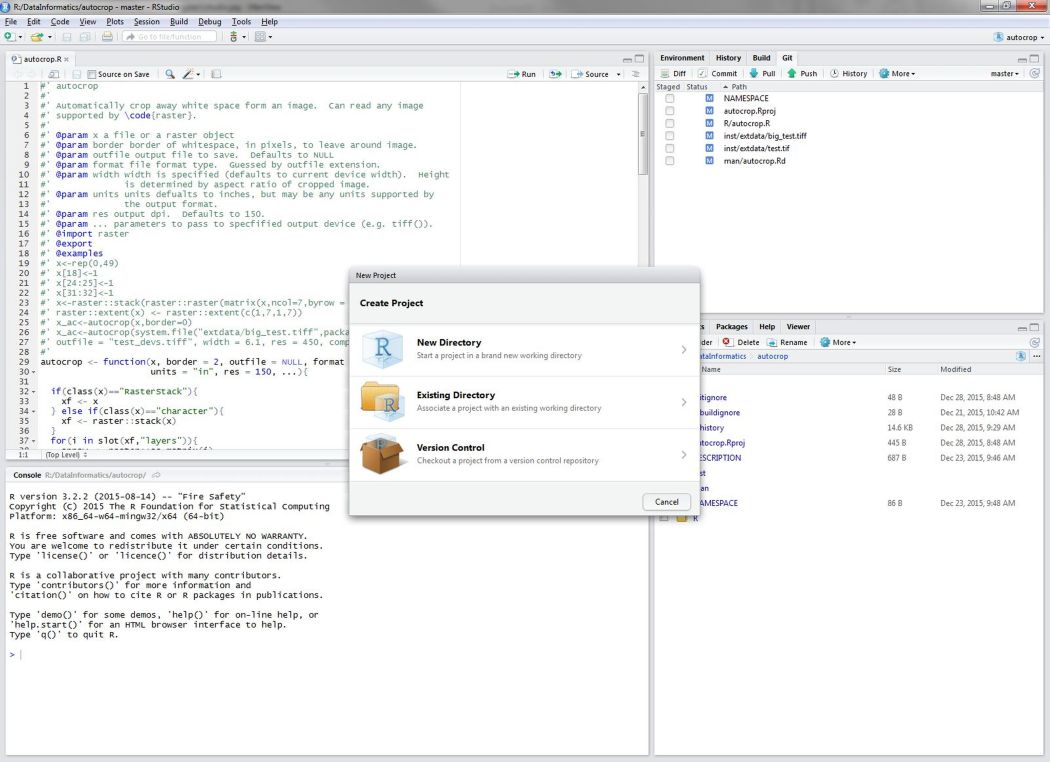
Now we can use this project for our data and any scripts we create.
Scripting
In most cases, you will not enter and execute code directly in the console. Code can be written in a script and then sent directly to the console when you’re ready to run it. The key difference here is that a script can be saved and shared.
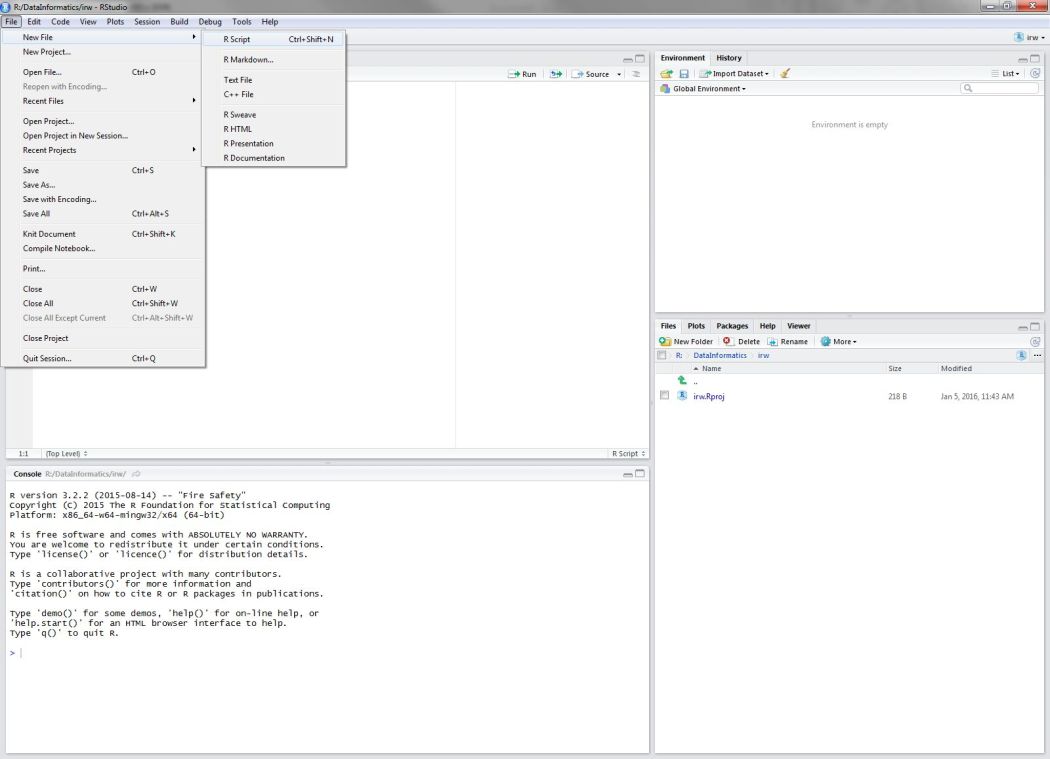
Open a new script from the File menu…
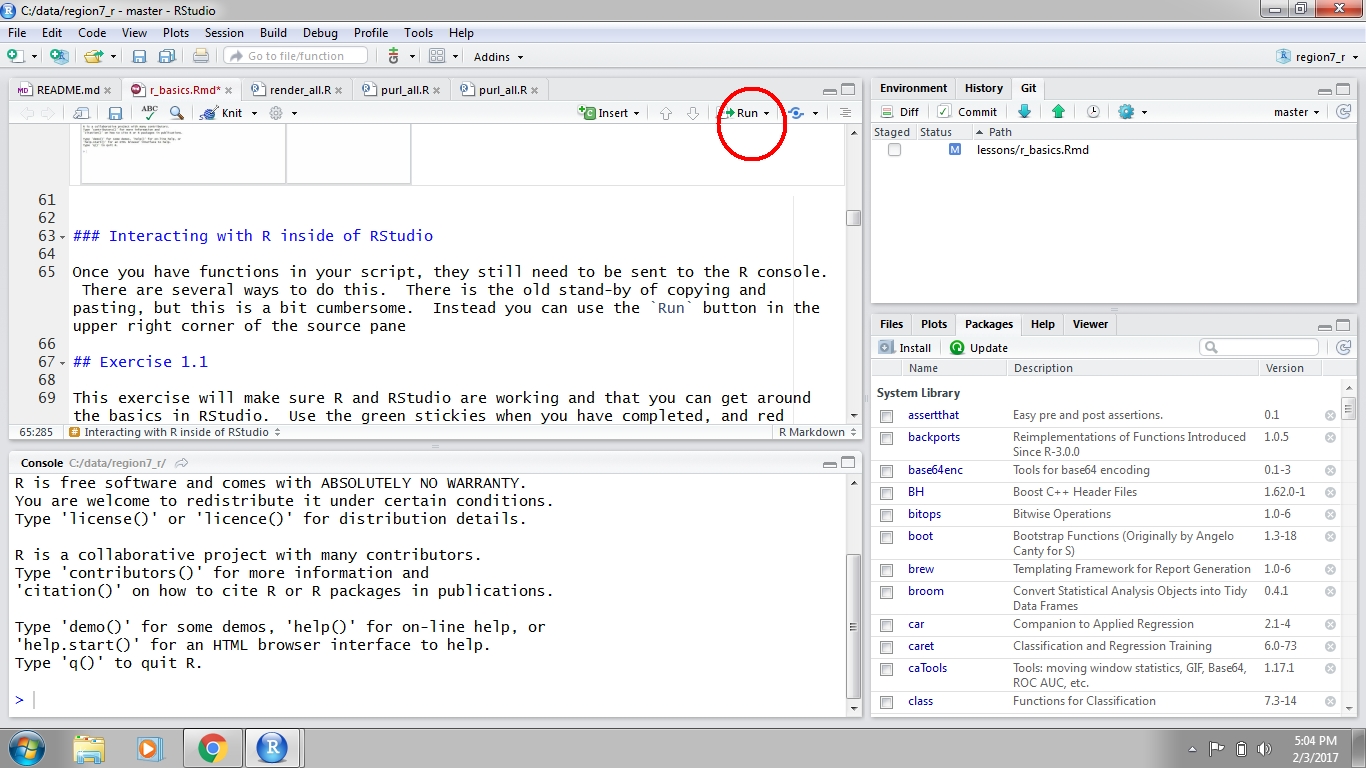
Executing code in RStudio
After you write code in your script, it can be sent to the Console to run the code in R. Anything you write in the script will not be run or saved in R until it is sent to the console. There are two ways to do this. First, you can hit the Run button at the top right of the scripting window. Second, you can use ctrl+enter (cmd+enter on a Mac). Both approaches will send the selected line to the console, then move to the next line in your script. You can also highlight and send an entire block of code.
Exercise 1
This exercise will make sure R and RStudio are working and that you can get around the basics in RStudio.
Start RStudio if using a version you installed OR navigate to https://rstudio.cloud/project/1318333 if using RStudio Cloud. To start both R and RStudio requires only firing up RStudio. RStudio should be available from All Programs at the Start Menu. Fire up RStudio.
If you’re not using RStudio Cloud, create a new project (File menu, New project, New directory, New project, Directory Name…). Name it “r_workshop”. We will use this for the rest of the workshop.
Create a new “R Script” in the Source Pane, save that file into your newly created project and name it “first_script.R”. It’ll just be a blank text file at this point.
Add in a comment line to separate this section. It should look something like:
# Exercise 1: Just Getting used to RStudio and Scripts.Lastly, we need to get this project set up with some example data for our exercises (if you’re using RStudio Cloud, ignore this step). You should have downloaded this already, but if not, the data are available here. The data are in a zipped folder. Download the file to your computer (anywhere). Create a folder in your new project named
dataand extract the files into this location.
R language fundamentals
R is built around functions. These are commands that do specific things based on what you provide. The basic syntax of a function follows the form: function_name(arg1, arg2, ...).
With the base install, you will gain access to many functions (3813, to be exact). Some examples:
# print
print('hello world!')## [1] "hello world!"# sequence
seq(1, 10)## [1] 1 2 3 4 5 6 7 8 9 10# random numbers
rnorm(100, mean = 10, sd = 2)## [1] 9.515524 10.387648 9.330865 9.937639 15.173624 9.755387 10.053197
## [8] 12.026068 10.254522 11.311913 9.212438 10.772671 12.025905 12.143794
## [15] 11.129311 15.235886 9.052250 7.623404 10.437346 12.569324 5.318555
## [22] 13.704500 8.809425 10.038005 10.555874 9.972604 11.215663 9.093054
## [29] 9.469838 10.131670 12.015468 11.627364 11.008364 12.992889 4.894744
## [36] 11.473410 16.818322 13.561521 9.161741 9.445026 13.082480 9.380048
## [43] 11.676142 8.981869 10.982992 11.117855 9.003581 9.453374 8.700419
## [50] 11.374864 8.917515 8.697298 12.523493 12.933565 12.372217 10.081599
## [57] 10.172981 9.052852 7.493094 10.489881 9.280688 9.094326 11.058797
## [64] 6.837192 9.315553 7.769018 11.293130 9.782203 7.578923 11.371979
## [71] 12.676619 11.055435 10.793742 10.138712 13.778246 9.922188 10.504992
## [78] 10.159337 9.267272 9.916807 13.051147 9.035931 10.598369 9.134227
## [85] 10.450397 12.727803 11.383838 12.139811 8.123777 11.633742 11.888562
## [92] 10.651049 7.738851 7.080023 9.144406 11.606789 10.741442 13.062311
## [99] 8.111122 9.642038# average
mean(rnorm(100))## [1] 0.1414498# sum
sum(rnorm(100))## [1] -8.166785Very often you will see functions used like this:
my_random_sum <- sum(rnorm(100))In this case the first part of the line is the name of an object. You make this up. Ideally it should have some meaning, but the only rules are that it can’t start with a number and must not have any spaces. The second bit, <-, is the assignment operator. This tells R to take the result of sum(rnorm(100)) and store it in an object named, my_random_sum. It is stored in the environment and can be used by just executing it’s name in the console.
my_random_sum## [1] 4.49654What is the environment?
There are two outcomes when you run code. First, the code will simply print output directly in the console. Second, there is no output because you have stored it as a variable using <-. Output that is stored is actually saved in the environment. The environment is the collection of named objects that are stored in memory for your current R session. Anything stored in memory will be accessible by it’s name without running the original script that was used to create it.
With this, you have the very basics of how we write R code and save objects that can be used later.
Packages
The base install of R is quite powerful, but you will soon have a need or desire to go beyond this. Packages provide this ability. They are a standardized way of extending R with new methods, techniques, and programming functionality. There is a lot to say about packages regarding finding them, using them, etc., but for now let’s focus just on the basics.
CRAN
One of the reasons for R’s popularity is CRAN, The Comprehensive R Archive Network. This is where you download R and also where most will gain access to packages (there are other places, but that is for later). Not much else to say about this now other than to be aware of it. As of 2021-04-02, there are 17352 packages on CRAN!
Installing packages
When a package gets installed, that means the source code is downloaded and put into your library. A default library location is set for you so no need to worry about that. In fact, on Windows most of this is pretty automatic. Let’s give it a shot.
Exercise 2
We’re going to install some packages from CRAN that will give us the tools for our workshop today. We’ll use the tidyverse, sf, and mapview packages. Later, we’ll explain in detail what each of these packages provide. Again, if you are using RStudio Cloud, these packages will already be installed. You can skip to step 5 in this case.
At the top of the script you just created, type the following functions.
# install packages from CRAN install.packages("tidyverse") install.packages("sf") install.packages("mapview")Select all the lines by clicking and dragging the mouse pointer over the text.
Send all the commands to the console using
ctrl+enter. You should see some text output on the console about the installation process. The installation may take a few minutes so don’t be alarmed.After the packages are done installing, verify that there were no errors during the process (this should be pretty obvious, i.e., error text in big scary red letters).
Load the packages after they’ve installed.
library("tidyverse") library("sf") library("mapview")
An important aspect of packages is that you only need to download them once, but every time you start RStudio you need to load them with the library() function. Loading a package makes all of its functions available in your current R session.
Getting Help
Being able to find help and interpret that help is probably one of the most important skills for learning a new language. R is no different. Help on functions and packages can be accessed directly from R, can be found on CRAN and other official R resources, searched on Google, found on StackOverflow, or from any number of fantastic online resources. I will cover a few of these here.
Help from the console
Getting help from the console is straightforward and can be done numerous ways.
# Using the help command/shortcut
# When you know the name of a function
help("print") # Help on the print command
?print # Help on the print command using the `?` shortcut
# When you know the name of the package
help(package = "sf") # Help on the package `dplyr`
# Don't know the exact name or just part of it
apropos("print") # Returns all available functions with "print" in the name
??print # shortcut, but also searches demos and vignettes in a formatted pageOfficial R Resources
In addition to help from within R itself, CRAN and the R-Project have many resources available for support. Two of the most notable are the mailing lists and the task views.
- R Help Mailing List: The main mailing list for R help. Can be a bit daunting and some (although not most) senior folks can be, um, curmudgeonly…
- R-sig-ecology: A special interest group for use of R in ecology. Less daunting than the main help with participation from some big names in ecological modelling and statistics (e.g., Ben Bolker, Gavin Simpson, and Phil Dixon).
- Environmetrics Task View: Task views are great in that they provide an annotated list of packages relevant to a particular field. This one is maintained by Gavin Simpson and has great info on packages relevant to the environmental sciences.
- Spatial Analysis Task View: One I use a lot that lists all the relevant packages for spatial analysis, GIS, and Remote Sensing in R.
Google and StackOverflow
While the resources already mentioned are useful, often the quickest way is to just turn to Google. However, a search for “R” is a bit challenging. A few ways around this. Google works great if you search for a given package or function name. You can also search for mailing lists directly (i.e. “R-sig-geo”), although Google often finds results from these sources.
Blind googling can require a bit of strategy to get the info you want. Some pointers:
- Always preface the search with “r”
- Understand which sources are reliable
- Take note of the number of hits and date of a web page
- When in doubt, search with the exact error message (see here for details about warnings vs errors)
One specific resource that I use quite a bit is StackOverflow with the ‘r’ tag. StackOverflow is a discussion forum for all things related to programming. You can then use this tag and the search functions in StackOverflow and find answers to almost anything you can think of. However, these forums are also very strict and I typically use them to find answers, not to ask questions.
Other Resources
As I mentioned earlier, there are TOO many resources to list here and everyone has their favorites. Below are just a few that I like.
- R For Cats: Basic introduction site, meant to be a gentle and light-hearted introduction
- R for Data Science: My favorite resource for learning data science methods with R, focusing on the tidyverse. Much of the content in this training is adapted from this book.
- Advanced R: Web home of Hadley Wickham’s book, the same author of R for Data Science. Gets into more advanced topics, but also covers the basics in a great way.
- CRAN Cheatsheets: A good cheat sheet from the official source
- RStudio Cheatsheets: Additional cheat sheets from RStudio. I am especially fond of the data wrangling one.
Data structures in R
Now that you know how to get started in R and where to find resources, we can begin talking about R data structures. Simply put, a data structure is a way for programming languages to handle information storage.
There is a bewildering amount of formats for storing data and R is no exception. Understanding the basic building blocks that make up data types is essential. All functions in R require specific types of input data and the key to using functions is knowing how these types relate to each other.
Vectors (one-dimensional data)
The basic data format in R is a vector - a one-dimensional grouping of elements that have the same type. These are all vectors and they are created with the c function:
dbl_var <- c(1, 2.5, 4.5)
int_var <- c(1L, 6L, 10L)
log_var <- c(TRUE, FALSE, T, F)
chr_var <- c("a", "b", "c")The four types of atomic vectors (think atoms that make up a molecule aka vector) are double (or numeric), integer, logical, and character. For most purposes you can ignore the integer class, so there are basically three types. Each type has some useful properties:
class(dbl_var)## [1] "numeric"length(log_var)## [1] 4These properties are useful for not only describing an object, but they define limits on which functions or types of operations that can be used. That is, some functions require a character string input while others require a numeric input. Similarly, vectors of different types or properties may not play well together. Let’s look at some examples:
# taking the mean of a character vector
mean(chr_var)
# adding two numeric vectors of different lengths
vec1 <- c(1, 2, 3, 4)
vec2 <- c(2, 3, 5)
vec1 + vec22-dimensional data
A collection of vectors represented as one data object are often described as two-dimensional data, or in R speak, a data frame (i.e., data.frame()). Think of them like your standard spreadsheet, where each column describes a variable (vector) and rows link observations between columns. Here’s a simple example:
ltrs <- c('a', 'b', 'c')
nums <- c(1, 2, 3)
logs <- c(T, F, T)
mydf <- data.frame(ltrs, nums, logs)
mydf## ltrs nums logs
## 1 a 1 TRUE
## 2 b 2 FALSE
## 3 c 3 TRUEThe only constraints required to make a data frame are:
Each column (vector) contains the same type of data
The number of observations in each column is equal.
Getting your data into R
It is the rare case when you manually enter your data in R, not to mention impractical for most datasets. Most data analysis workflows typically begin with importing a dataset from an external source. Literally, this means committing a dataset to memory (i.e., storing it as a variable) as one of R’s data structure formats.
Flat data files (text only, rectangular format) present the least complications on import because there is very little to assume about the structure of the data. On import, R tries to guess the data type for each column and this is fairly unambiguous with flat files. We’ll be using read_csv() function from the readr package that comes with the tidyverse.
The working directory
Before we import data, we need to talk about the “working directory”. Whenever RStudio is opened, it uses a file location on your computer to access and save data. If you’re using an RStudio project, the working directory will be the folder where you created the project. If not, it is probably the the user’s home directory (e.g., C:/Users/Marcus), which you’ll want to change to where you have your data.
You can see your working directory with the getwd() function or from the file path at the top of the console in RStudio. All files in the File pane window on the bottom right of RStudio are also those within the working directory. If you want to change your working directory, you can use the setwd() function and put the file path (as a character string) inside the function, e.g., setwd('C:/Users/Marcus/Desktop/newdirectory').
The working directory is important to know when you’re importing or exporting data. When you import data, a relative file path can be used that is an extension of the working directory. For example, if your working directory is 'C:/Users/Marcus/Desktop' and you have a file called mydata.csv in that directory, you can use read_csv('mydata.csv') to import the file. Alternatively, if there’s a folder called “data” in your working directory with the file you want to import, you would use read_csv('data/mydata.csv').
If you want to import a file that is not in your working directory, you will have to use an absolute path that is the full file location. Otherwise, R will not know where to look outside of the working directory.
Exercise 3
Now that we have the data downloaded and extracted to our data folder, we’ll use read_csv to import two files into our environment. The read_csv function comes with the tidyverse package, so make sure that package is loaded (i.e., library(tidyverse)) before you do this exercise. This should have been done in the second exercise.
Type the following in your script. Note the use of relative file paths within your project (see the explanation above).
fishdat <- read_csv('data/fishdat.csv') statloc <- read_csv('data/statloc.csv')Send the commands to the console with
ctrl+enter.Verify that the data imported correctly by viewing the first six rows of each dataset. Use the
head()function directly in the console, e.g.,head(fishdat)orhead(statloc)
Let’s explore the datasets a bit. There are many useful functions for exploring the characteristics of a dataset. This is always a good idea when you first import something.
# get the dimensions
dim(fishdat)## [1] 2844 12dim(statloc)## [1] 2173 3# get the column names
names(fishdat)## [1] "OBJECTID" "Reference" "Sampling_Date" "yr"
## [5] "Gear" "ExDate" "Bluefish" "Common Snook"
## [9] "Mullets" "Pinfish" "Red Drum" "Sand Seatrout"names(statloc)## [1] "Reference" "Latitude" "Longitude"# see the first six rows
head(fishdat)## # A tibble: 6 x 12
## OBJECTID Reference Sampling_Date yr Gear ExDate Bluefish
## <dbl> <chr> <date> <dbl> <dbl> <dttm> <dbl>
## 1 1550020 TBM1996032006 1996-03-20 1996 300 2018-04-12 10:27:38 0
## 2 1550749 TBM1996032004 1996-03-20 1996 22 2018-04-12 10:25:23 0
## 3 1550750 TBM1996032004 1996-03-20 1996 22 2018-04-12 10:25:23 0
## 4 1550762 TBM1996032207 1996-03-22 1996 20 2018-04-12 10:25:23 0
## 5 1550828 TBM1996042601 1996-04-26 1996 160 2018-04-12 10:25:23 0
## 6 1550838 TBM1996051312 1996-05-13 1996 300 2018-04-12 10:25:23 0
## # ... with 5 more variables: Common Snook <dbl>, Mullets <dbl>, Pinfish <dbl>,
## # Red Drum <dbl>, Sand Seatrout <dbl>head(statloc)## # A tibble: 6 x 3
## Reference Latitude Longitude
## <chr> <dbl> <dbl>
## 1 TBM1996032006 27.9 -82.6
## 2 TBM1996032004 27.9 -82.6
## 3 TBM1996032207 27.9 -82.5
## 4 TBM1996042601 28.0 -82.7
## 5 TBM1996051312 27.9 -82.6
## 6 TBM1996051407 27.9 -82.6# get the overall structure
str(fishdat)## spec_tbl_df[,12] [2,844 x 12] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ OBJECTID : num [1:2844] 1550020 1550749 1550750 1550762 1550828 ...
## $ Reference : chr [1:2844] "TBM1996032006" "TBM1996032004" "TBM1996032004" "TBM1996032207" ...
## $ Sampling_Date: Date[1:2844], format: "1996-03-20" "1996-03-20" ...
## $ yr : num [1:2844] 1996 1996 1996 1996 1996 ...
## $ Gear : num [1:2844] 300 22 22 20 160 300 300 300 300 22 ...
## $ ExDate : POSIXct[1:2844], format: "2018-04-12 10:27:38" "2018-04-12 10:25:23" ...
## $ Bluefish : num [1:2844] 0 0 0 0 0 0 0 0 0 0 ...
## $ Common Snook : num [1:2844] 0 0 0 0 0 0 0 0 0 0 ...
## $ Mullets : num [1:2844] 0 0 0 0 0 0 0 0 0 0 ...
## $ Pinfish : num [1:2844] 0 54 0 80 0 0 0 0 1 1 ...
## $ Red Drum : num [1:2844] 0 0 1 0 4 0 0 0 0 0 ...
## $ Sand Seatrout: num [1:2844] 1 0 0 0 0 1 5 66 0 0 ...
## - attr(*, "spec")=
## .. cols(
## .. OBJECTID = col_double(),
## .. Reference = col_character(),
## .. Sampling_Date = col_date(format = ""),
## .. yr = col_double(),
## .. Gear = col_double(),
## .. ExDate = col_datetime(format = ""),
## .. Bluefish = col_double(),
## .. `Common Snook` = col_double(),
## .. Mullets = col_double(),
## .. Pinfish = col_double(),
## .. `Red Drum` = col_double(),
## .. `Sand Seatrout` = col_double()
## .. )str(statloc)## spec_tbl_df[,3] [2,173 x 3] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ Reference: chr [1:2173] "TBM1996032006" "TBM1996032004" "TBM1996032207" "TBM1996042601" ...
## $ Latitude : num [1:2173] 27.9 27.9 27.9 28 27.9 ...
## $ Longitude: num [1:2173] -82.6 -82.6 -82.5 -82.7 -82.6 ...
## - attr(*, "spec")=
## .. cols(
## .. Reference = col_character(),
## .. Latitude = col_double(),
## .. Longitude = col_double()
## .. )You can also view each dataset in a spreadsheet style in the scripting window:
View(fishdat)
View(statloc)Other ways to import data
You might want to import an Excel spreadsheet as well. In the old days, importing spreadsheets into R was almost impossible given the proprietary data structure used by Microsoft. The tools available in R have since matured and it’s now pretty painless to import a spreadsheet. The readxl package is the most recent and by far most flexible data import package for Excel files. It comes with the tidyverse family of packages.
Once installed, we can load it to access the import functions.
library(readxl)
dat <- read_excel('location/of/excel/file.xlsx')Summary
In this lesson we learned about R and Rstudio, some of the basic syntax and data structures in R, and how to import files. We’ve just imported some provisional fisheries data from the FWRI FIM database for Old Tampa Bay (OTB) that we’ll continue to use for the rest of the workshop. Next we’ll learn how to process and plot these data to gain insight into how these data vary through space and time.